英文分词
使用tm包词频统计
tm包词频统计文本预处理
词频统计
代码实现
library(tm)
get_word_counts <-function(text){
# 分词
corpus <- VCorpus(VectorSource(text))
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeWords, stopwords("english"))
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_map(corpus, stemDocument)
# 统计词频
tdm <- TermDocumentMatrix(corpus)
freq_terms <- findFreqTerms(tdm, lowfreq = 50)
word_counts <- rowSums(as.matrix(tdm))
word_counts <- sort(word_counts, decreasing = TRUE)
return(word_counts)
}使用wordcloud绘制词云
wordcloud绘制词云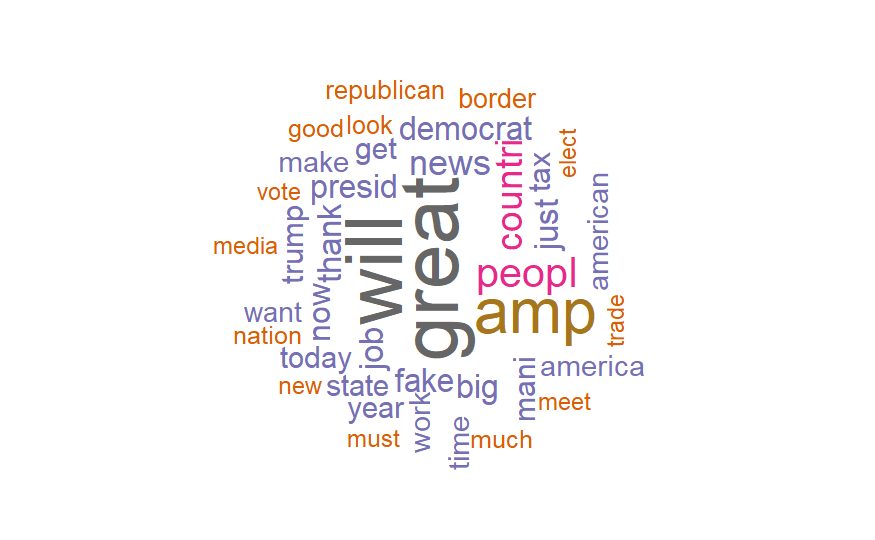
最后更新于